作为开发者,中文字符的编码问题多多少少会遇到。
最近在处理天气的 API 时候再次遇到了点中文编码问题,所以决定记录一下 Python 中常见的编码问题。
ASCII、Unicode 和 UTF-8
ASCII 码
美国用的标准信息交换码。ASIIC 码包括大小写英文字母、数字和一些符号,使用用二进制来表示,一共 128 个,1 字节 (byte)=8bit,8bit 能表示的最大数是 256,所以 ASIIC 编码中一个字符的大小就是 1 个字节。
Unicode 编码
ASIIC 码的扩展,Unicode 把所有语言都统一到一套编码里,称为万国语言。特点:速度快,但浪费空间。
UTF-8 编码
将 Unicode 编码转化为 “可变长编码” 的 UTF-8 编码。UTF-8 编码把一个 Unicode 字符根据不同的数字大小编码成 1-6 个字节,常用的英文字母被编码成 1 个字节,汉字通常是 3 个字节,只有很生僻的字符会被编码成 4-6 个字节。
ASCII、Unicode 和 UTF-8 的关系

从上面的表格还可以发现,是 ASCII 编码实际上可以被看成是 UTF-8 编码的一部分。所以,大量只支持 ASCII 编码的历史遗留软件可以在 UTF-8 编码下继续工作。
Python 的字符串类型
Python2 和 Python3 的字符串类型
Python 2 版本中,字符串的类型:str 和 bytes。默认以 ASCII 编码
Python 3 版本中,字符串的类型:Unicode 和 str。默认以 Unicode 编码。
Python2 和 Python3 字符串类型对应关系
Python2 和 Python3 字符串类型对应关系如下:
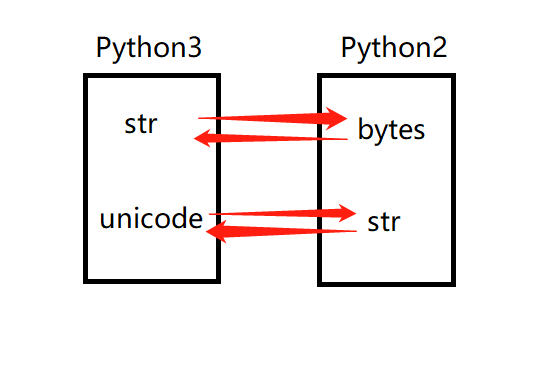
在 Python2 中,str 与 Unicode 需要转换,转换如下:
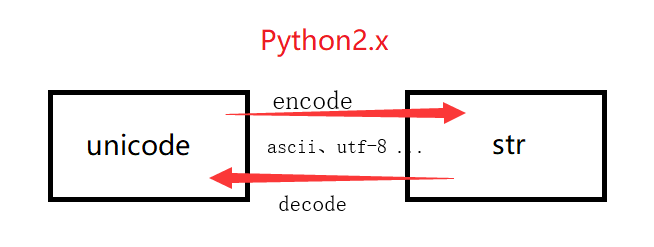
str –> decode(解码)方法 –> Unicode –> encode(编码)方法 –> str
在 Python3 中,str 与 bytes 需要转换,转换如下:
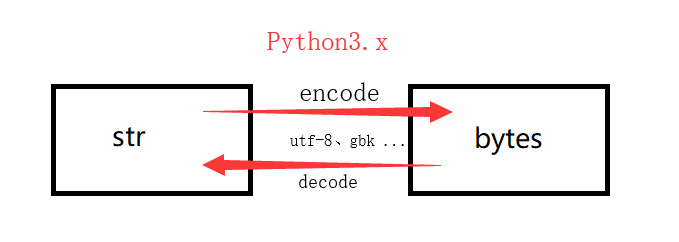
bytes –> decode(解码)方法 –> str –> encode(编码)方法 –> bytes
------------------ 在 Python2 中 -----------------------------
>>> type('x') # 'x'是 str,一个字符对应一个字节
<type 'str'>
>>>
>>> type(u'x'.encode('utf-8')) # Unicode 转换成 str
<type 'str'>
>>>
>>> type(u'中文'.encode('utf-8')) # Unicode 转换成 str
<type 'str'>
>>>
>>> type('x'.decode('utf-8')) # str 转换成 Unicode
<type 'Unicode'>
------------------ 在 Python3 中 -----------------------------
>>> type('x') # 'x'是 str,在内存中以 Unicode 表示,一个字符对应多个字节
<class 'str'>
>>>
>>> type(b'x') # b'x'是 bytes,与上面的 str 的区别是一个字符只占一个字节
<class 'bytes'>
>>>
>>> type(b'x'.decode('utf-8')) # bytes 转换成 str,可以用 UTF-8 编码
<class 'str'>
>>>
>>> type('中文'.encode('utf-8')) # 含有中文的 str 可以用 UTF-8 编码为 bytes
<class 'bytes'>
Python 中有一个是隐式的转换的规则,当一个 Unicode 字符串和一个 str 字符串进行连接的时候,会自动将 str 字符串转换成 Unicode 类型然后再连接,而这个时候使用的编码方式则是系统所默认的编码方式。Python2 默认使用 ASCII,Python3 默认使用 utf-8。
Python3 字符串改进之处
在 Python 3.0 之后的版本中,所有的字符串都是使用 Unicode 编码的字符串序列,同时还有以下几个改进:
-
默认编码格式改为 Unicode
-
所有的 Python 内置模块都支持 Unicode
-
不再支持 u’中文’的语法格式
Python 中编码错误汇总
1、 SyntaxError: (Unicode error) ‘utf-8’ codec can’t decode byte 0xc4 in position 0: invalid continuation byte
Python3.X 源码文件默认使用 utf-8 编码,所以可以正常解析中文,无需指定 UTF-8 编码。
如果使用编辑器 Pycharm,需要设置 py 文件存储的格式为 UTF-8,否则会出现类似如题错误信息
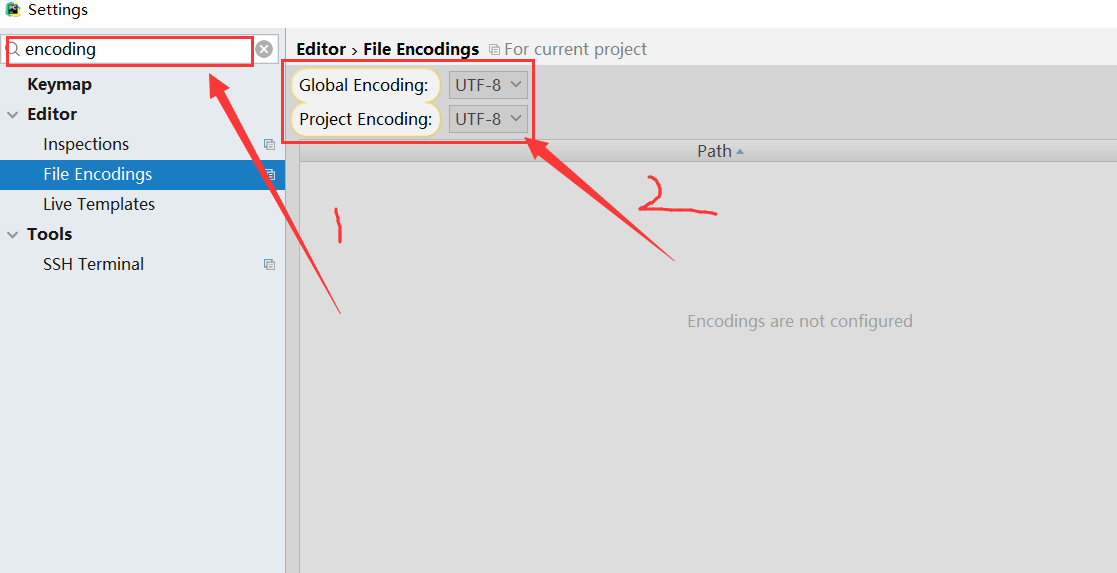
Pycharm 设置步骤:
- 进入 file > Settings,在输入框搜索 encoding。
- 找到 Editor > File encodings,将 IDE Encoding 和 Project Encoding 设置为 utf-8。
2、 SyntaxError: Non-ASCII character ‘\xe4’ in file test.py on line 2, but no encoding declared;
Python2.x 中默认的编码格式是 ASCII 格式,在没修改编码格式时无法正确打印汉字,所以在读取中文时会报错。
解决方法:在文件开头加入 # -*- coding: UTF-8 -*- 或者 #coding=utf-8
注意:#coding=utf-8 的 = 号两边不要空格。
3、 UnicodeEncodeError: ‘ASCII’ codec can’t encode characters in position 0-1: ordinal not in range(128)
URL 中的中文编码问题
报错代码片段如下:
import urllib.request
url = 'https://www.sojson.com/open/api/weather/json.shtml?city=%s' % city_name
urlobject = urllib.request.urlopen(url)
报错代码截图如下:
解决办法:
Python3 urllib.request.urlopen(url) 中,url 地址中不能出现中文,而上述代码的 city=%s 传入了中文字符,所以出现了上述报错信息。
如果 url 中存在中文或者特殊字符需要进行特殊处理。
-
导入 quote 方法
from urllib.parse import quote -
导入 string 模块
import string -
在进行 urlopen(url) 前,先对 url = quote(url, safe=string.printable)
-
方法 quote 的参数 safe 表示可以忽略的字符。
string.printable 表示 ASCII 码第 33~126 号可打印字符,其中第 48~57 号为 0~9 十个阿拉伯数字;65~90 号为 26 个大写英文字母,97~122 号为 26 个小写英文字母,其余的是一些标点符号、运算符号等。
如果去掉 safe 参数的内容将会出错。
import urllib.request
from urllib.parse import quote
import string
url = 'https://www.sojson.com/open/api/weather/json.shtml?city=%s' % city_name
url = quote(url, safe=string.printable) # URL 带中文、特殊字符(空格)的特殊处理
urlobject = urllib.request.urlopen(url)
Python2.x 中的用法:urllib.quote(text)
4、 UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xff in position 3: invalid start byte
>>> s = u"中文"
>>> s
u'\u4f60\u597d'
>>> str(s)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ASCII' codec can't encode characters in position 0-1: ordinal not in range(128)
上述代码在 Python2 环境下报错,s 是 Unicode 类型的字符串,所以在执行 str(s) 时会相应的转换成 Python 默认编码,也就是 ASCII 码,相当于是执行 s3.encode('ASCII'),而 ` 中文 ` 不能使用 ASCII 码来表示。正确处理是 s3.encode('gbk') 或 s3.encode('utf-8')
总结
- Python3 的 str == Python2 中的 Unicode
- 字符编码声明:在代码开头声明编码格式
- 尽可能使用 Unicode 而不是 str
- Windows 下默认编码是 GBK,所以 cmd 下编程是 GBK 编码
常见编码错误的原因有:
- Python 解释器的默认编码
- Python 源文件文件编码
- Terminal 使用的编码
- 操作系统的语言设置